
原文标题:A Machine Learning Approach to Classify Network Traffic
原文作者:Nilesh Jadav, Nitul Dutta, Hiren Kumar Deva Sarma, Emil Pricop
原文链接:https://doi.org/10.1109/ECAI52376.2021.9515039
发表会议:13th International Conference on Electronics, Computers and Artificial Intelligence (ECAI)
笔记作者:宋坤书@安全学术圈
1、研究背景
互联网中每天都会发生多种数字犯罪,如分布式拒绝服务攻击(DDoS)、恶意软件攻击、中间人 攻击(MiTM)等,传统的防御措施(防火墙、访问控制、检测与预防系统)虽然在资源保护方面发挥重要作用,但仍然无法有效应对这些攻击行为。随着多种加密技术(SSL、HTTPS、VPN等)的使用,网络流量分析变得更加困难,攻击者可以采用绕过传统的防御机制(协议分析器、深度包检测),或者将流量通过Tor网络的隐藏服务传输。
对于网络管理员而言,区分攻击流量和正常流量是一项艰巨的任务。虽然基于规则的学习方法在防火墙和检测系统中可以用来标记攻击流量,但这些方法容易被攻击者规避。相反,机器学习(ML)和深度学习(DL)在网络流量分类中表现出色,通过算法可以对流量进行有效分类。本文探讨了多种机器学习算法在流量分类中的应用,旨在解决区分攻击流量和正常流量的二分类问题,提高网络安全防御能力。
2、使用的数据集
本文使用的数据集是由加拿大网络安全研究所(CIC)创建的Darknet 2020数据集[1]。该数据集通过结合两个公开数据集ISCXTor2016和ISCXVPN2016创建,主要包含Tor流量和VPN流量,构成了一个复杂的暗网数据集。Darknet 2020数据集有141530行数据和85个特征,目标输出为二分类:Benign(良性流量)和Darknet(暗网流量)。
3、网络流量分类方法
本文的研究核心是网络流量分类,主要步骤包括数据预处理与特征提取、数据集不平衡处理和分类算法选择。
3.1 数据预处理与特征提取
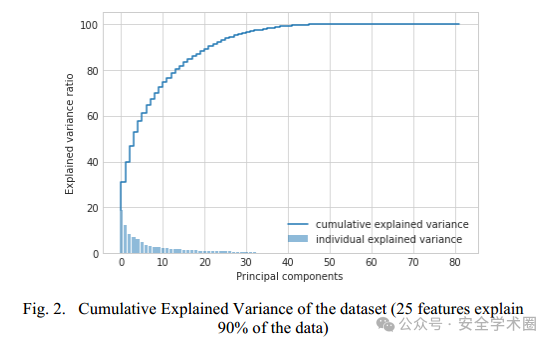
使用主成分分析(PCA)对数据进行降维,首先,对数据进行标准化处理,确保每个特征对结果的贡献是平等的。然后通过计算选择主要特征,将原始的85个特征降维到25个,这些特征可以解释90%的数据方差,这样减少计算复杂度。具体步骤如下:
特征标准化:通过减去每个特征的均值并除以其标准差来实现标准化; 计算协方差矩阵:矩阵对角线元素是各个特征的方差,非对角线元素是特征之间的协方差,可以用来衡量特征之间的线性关系; 计算特征值和特征向量:求解协方差矩阵的特征值和特征向量; 选择主成分:根据特征值的大小排序,选择前25个最大的特征值对应的特征向量; 投影数据:将原始数据投影到新的特征空间,实现降维。
数据集的累积解释方差如下:
3.2 数据集不平衡处理
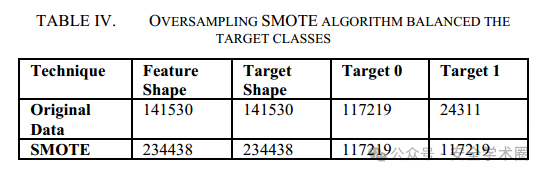
由于数据集中“Benign”样本数量远多于“Darknet”样本,导致数据集不平衡,因此本文采用合成少数类过采样技术(SMOTE)来平衡数据集。首先,对于每个少数类样本计算其与最近邻样本之间的差异。然后,利用这个差异生成新的合成样本。具体做法是将差异乘以一个介于0和1之间的随机数,并将结果加到原始样本上,生成一个新的合成样本。通过这种方法,SMOTE可以在原始样本和其邻居之间的连线中生成新样本,增加少数类的样本数量,从而平衡数据集。应用SMOTE算法后的数据集变化如下表:
3.3 分类算法选择
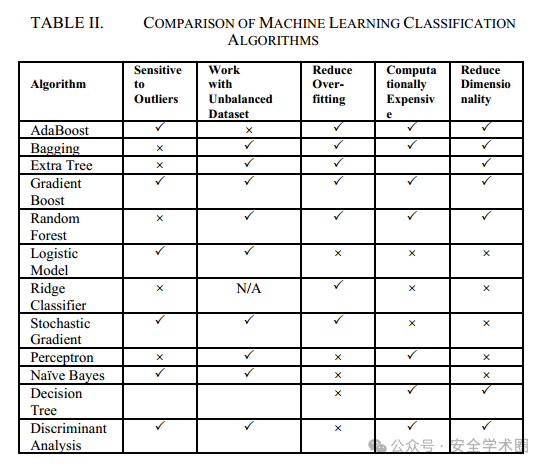
本文选择了多种常见的机器学习算法进行实验,包括AdaBoost、Bagging、Extra Trees、Gradient Boosting、Random Forest、Decision Tree、Logistic Regression和SGD等。评估指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1-Score和马修斯相关系数(MCC)。不同机器学习分类算法比较如下:
4、分类结果与性能分析
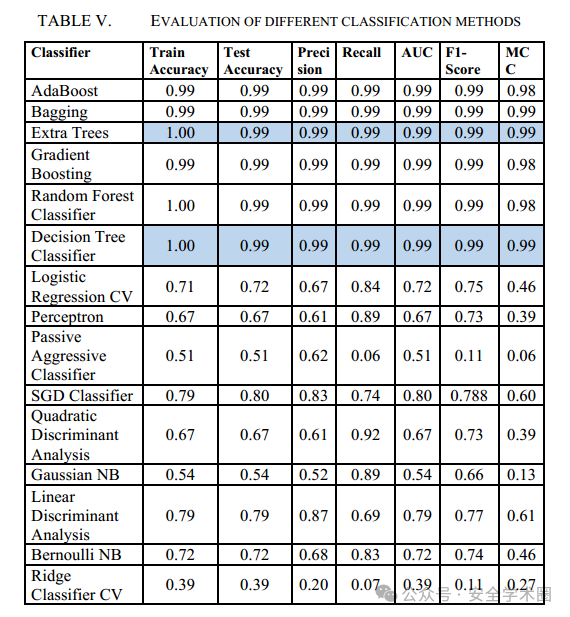
在分类算法的评估中,Extra Tree(极端随机树)和Decision Tree(决策树)表现最佳,能够有效区分“恶意流量”和“正常流量”。这两个算法在准确率、F1-Score和MCC上表现均优于其他算法,特别是在处理不平衡数据时,它们在精确率与召回率之间找到良好平衡,避免了过拟合问题。不同机器学习算法的分类效果评估如下:
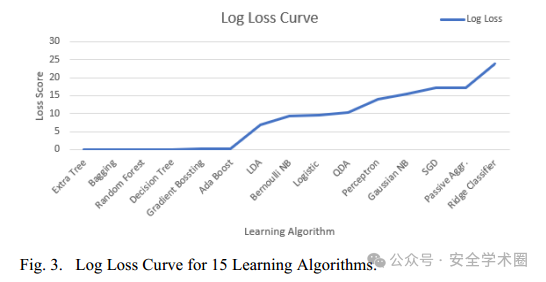
通过Log Loss(对数损失)和ROC曲线也可以看出Extra Tree和Desicion Tree具有较高的预测精度。它们的对数损失分分别为0.028和0.030,这表明它们在概率预测方面表现较好。同时,ROC曲线分析显示,这两种模型在不同阈值下均能保持较低的假正率和较高的真正率,这说明它们具有较好的分类能力。不同机器学习算法的对数损失曲线如下:
5、总结
本文提出了一种基于机器学习的网络流量分类方法,旨在区分正常流量和攻击流量。文中使用了CIC-Darknet 2020数据集,通过主成分分析(PCA)降低维度,并使用合成少数类过采样技术(SMOTE)平衡数据集。实验比较了多种机器学习算法,结果显示集成方法中的Extra Tree和Desicion Tree在各项评估指标上表现最佳,能够高效地区分“Benign”和“Darknet”。
研究的局限性:本文并未生成自己的数据集、也没有比较机器学习与深度学习算法的性能,未来开发更强大的多分类算法,以进一步分类TOR、VPN以及其他匿名网络的流量。
[1] A. Habibi Lashkari, G. Kaur, and A. Rahali, “DIDarknet: A Contemporary Approach to Detect and Characterize the Darknet Traffic using Deep Image Learning,” in 2020 the 10th International Conference on Communication and Network Security, Tokyo Japan, Nov. 2020, pp. 1–13. doi: 10.1145/3442520.3442521.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
专题最新征文
期刊征文 | 暗网抑制前沿进展 (中文核心)
期刊征文 | 网络攻击分析与研判 (CCF T2)
期刊征文 | 域名安全评估与风险预警 (CCF T2)